Wie nervige Buchstaben unser kulturelles Erbe retten.
Vor kurzem bin ich auf einen interessanten Artikel über CAPTCHAs und reCAPTCHAs gestoßen. Er hat mich dazu bewegt, mich ein wenig näher mit ihnen zu befassen. Sie sind ein nahezu allgegenwärtiges Phänomen des modernen Internet und eigentlich jedem bekannt, der häufiger mal seinen Senf dazu gibt oder ein Profil bei Facebook pflegt. CAPTCHAs sind in den meisten Fällen kurze, kryptische Buchstaben- oder Zahlenfolgen, die wir entziffern und in ein Feld schreiben müssen um fortzufahren. Sie sind dazu gedacht Spam zu bekämpfen, da sich Computer mit dem Lesen von Bildern nach wie vor sehr schwer tun. So nützlich sie sind, werden mir wohl doch die meisten zustimmen, dass sie mitunter ziemlich nervtötend sind. Stimmt doch, oder?
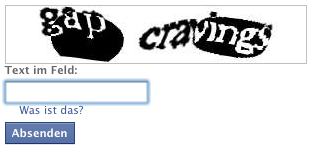
Nun, dann will ich euch den Nachfolger vorstellen, das reCAPTCHA. Es wurde von Luis von Ahn an der Carnegy Mellon University entwickelt und 2009 von Google übernommen. Man erkennt sie daran, dass man nun gleich 2 Wörter herausfinden muss, statt nur eines. Leider sind sie damit nicht weniger nervig als ihre Vorgänger, aber zumindest erfüllen sie nebenbei noch einen guten Zweck. Manche von uns versuchen immerhin ihr ganzes Leben lang einen guten Zweck zu erfüllen. Diese reCAPTCHAs machen das, in dem sie bei der Digitalisierung von Büchern und dem gesammelten Archiv der New York Times helfen.
Wie funktioniert das Ganze? Das Konzept selbst ist recht einfach, der Algorithmus dahinter wohl weniger. Eines der abgefragten Wörter stammt aus der Textanalysesoftware des Digitalisierungsprojektes und konnte von dieser nicht erkannt werden. Das andere Wort ist ein zufällig generiertes, aber der reCAPTCHA-Software bekanntes Wort, welches zur Kontrolle hinzugezogen wird. Die Verbreitung dieser Wortabfragen über weite Teile des Internets ermöglicht eine sehr zielsichere statistische Auswertung, welche Eingabevariante korrekt ist und damit das gesuchte Wort aus dem Urtext treffend „übersetzt“. Diese Lösung wird dann an das Digitalisierungsprojekt zurück gesendet. Einige sehr bekannte Seiten, die reCAPTCHAs einsetzen sind Facebook, Ticketmaster und Twitter. Aktuelle Schätzungen gehen von etwa 100 Millionen reCAPTCHA-Eingaben pro Tag aus. Nach Angaben von Google wären beim gegenwärtigen Tempo bis 2012 alle noch fehlenden Titel aus den letzten 110 Jahren des New York Times Archivs digitalisiert.
Wer angesichts der aktuellen Datenschutzdiskussionen eine leichte Beunruhigung verspürt, kann sich getrost wieder zurücklehnen. Es werden keine persönlichen Daten weitergeleitet, da diese den Service unnötig verlangsamen und die Server verstopfen würden.
Wenn ihr euch also das nächste Mal ärgert, weil ihr ein reCAPTCHA nicht beim ersten Mal lösen konntet, solltet ihr euch vielleicht eher über die Qualität der verwendeten Scanner beschweren. ;)
Wer sich noch weiter mit diesem spannenden Thema befassen will, kann einfach den markierten Links im Text folgen. Im Folgenden habe ich noch ein (englisches) Video angehängt, welches das Projekt ziemlich gut erläutert. Der Vortragende ist der Erfinder des CAPTCHA und ein ziemlich unterhaltsamer Typ. Viel Spaß.
Stephan de Paly – print24 Blogautor









